Architecture Details
Lets start the detailed architecture discussion by looking at what Cryptbreaker is running on your local system. Then we’ll walk through the configuration and cracking workflow and see how and when AWS resources are utilized.
Cryptbreaker Local Components
The Cryptbreaker application running on your local system is really two pieces: * a Meteor web application to provide a User Interface and interact with the local database and remote AWS resources * a MongoDB database used to store all the information that Cryptbreaker needs to be aware of

If you’re using the dockerized version of Cryptbreaker then the MongoDB service is only accessible to processes running within the container (in this way the Meteor process can access and use the database). To illustrate how local and cloud resources are orchestrated to provide functionality while maximizing security lets walk through initial Cryptbreaker setup and running a cracking job.
Initial Setup
Once Cryptbreaker is installed and running the first thing you’ll do is register an account in the application. When you perform this action a new user is added to the backend database stored on your local system.
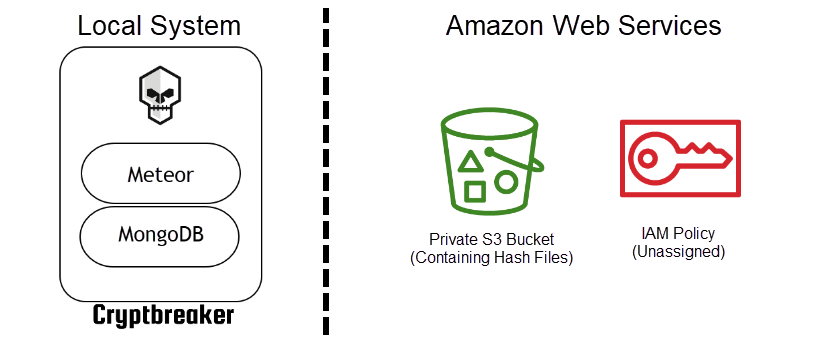
Upon sign-in the application next prompts for AWS access key information. When this information is provided to Cryptbreaker it saves the data as a credential in the local database. The application then prompts you to perform initial cloud configuration. During initial configuration a number of things occur: 1. A new private S3 bucket is created in your account. 2. The bucket has a default Access Control List (ACL) of private applied 3. A public access block is applied to the bucket 4. A new Identity Access Management Policy is created within the account that allows for full access to the S3 bucket created in the last step and also allows for the termination of EC2 instances (so that our cracking machines can terminate themselves once cracking is completed).
The combination of ‘Private’ ACLs on the S3 bucket and the specially crafted IAM Policy/Role effectively means that only the account owner (you) has the ability to access data in the S3 bucket. By creating the IAM role we allow our EC2 instances used for cracking to push and pull data from S3 and also terminate itself once cracking is complete.
At this point our AWS environment looks like this:

Uploading Hashes to Cryptbreaker
Suppose you want to crack hashes. The next step you might perform would be to upload a hash file to Cryptbreaker. When this happens Cryptbreaker will parse the hash file and store the data as hash objects in the local database tied to the file object representing the uploaded hash file.
Uploading hashes to Cryptbreaker has no effect on your AWS environment. All changes occur only in the local database.
Cracking Hashes with Cryptbreaker
When a crack job is submitted Cryptbreaker performs a few steps: 1. Checks with AWS to determine the cheapest spot prices currently available for each supported instance type in the regions enabled for cracking in Cryptbreaker. By default this is just the US regions. 2. Asks the user to select an instance type based off current pricing. 3. Prompts the user to choose a redaction level. By default Cryptbreaker does not perform redaction, you can modify this behavior to suit your needs. For the remainder of this example walkthrough we’ll assume that case based redaction has been selected (IE: Summer2019! -> Ulllll0000*) 4. Asks the user to confirm the chosen options.
Once you click ‘Submit’ Cryptbreaker makes a series of changes to the AWS environmennt to perforrm cracking. We’ll walkthrough each of these changes and show what the AWS environment looks like at step of the way.
Upload Hashes to S3
When a new hash cracking job is submitted Cryptbreaker first generates a list of unique hashes to crack based off of the hash files that have been queued for cracking. For each hash type contained in the specified hashes a new hash file is created. IE. if there are NTLM and LM hashes to be cracked 2 hash files will be generated: one containing only NTLM hashes and the other containing only LM hashes. The contents of these files are just the raw hash data (no user information or other hash metadata is saved).
Each of these hash files is then uploaded to the private S3 bucket to enable the cloud-based cracking system to retrieve their contents.
Our AWS environment now looks like this:
Provisioning of Cloud-Cracking System
With the necessary hash files successfully uploaded to S3 Cryptbreaker next will provision the user-specified class of machine via a spot request to perform cracking activities. When creating an EC2 instance there are a number of options that can be supplied. Cryptbreaker uses a number of these options to: 1. Upload a bash script to run once the system comes online 2. Assign the IAM Role/Profile previously configured to the system 3. Apply the default security group to the system
The default security group is a sort of firewall which (unless otherwise configured by the user in their AWS account) prevents all inbound communications by default. In addition to this protective measure to prevent access to the compute instance used for cracking Cryptbreaker disables SSH on system boot. It also requests an instance without specifying an SSH key to use which makes it impossible to authenticate to the system.
When the cloud-cracking system first comes online the environment looks like this:

Cracking Execution
All the cracking logic is contained in the initial bash script uploaded when the cracking instance is created. The script performs a number of actions:
1. Stop and Disable SSH
2. Perform system updates and install requirements
3. Write out periodic status files to S3 to enable Cryptbreaker to pull an update of what’s happening on the cracking box
4. Install NVidia Drivers
5. Install Hashcat
6. Download and Configure Cracking Wordlists and Rules
7. Download and delete credentials files from S3 as they are needed to perform cracking
8. Regularly poll S3 for a file indicating that cracking should be paused (and perform pause logic as necessary)
9. Sanitize password data (if configured) and enrich with what password lists they were observed on
10. Upload the cracked (and optionally sanitized) password file to S3
11. Self-terminate cracking instance to prevent further charges
A key note here is that once cracking begins hash files are removed from S3 and only exist on the cracking instance. Once cracking is complete and the EC2 instance has self-terminated the cracked hash information exists in the private S3 bucket.

Cryptbreaker Result Retrieval
Cryptbreaker polls S3 every minute during cracking execution to retrieve the most recent status update posted by the cloud-cracking instance and also to check for the final results being uploaded. Upon seeing the results file in S3 Cryptbreaker will download and then delete the cracked hashes file. Once retrieved, Cryptbreaker will parse the results and update it’s local database with the cracked information (plaintext or redacted content) and calculate applicable statistics. At this point the infrastructure looks exactly like it did upon initial configuration.
Hopefully this example walkthrough shows how and when information is passed to and utilized by AWS resources during the cracking process. For information on Getting Started see the next section.